CVG 1.29.1 (26-Apr-2023)
The simplicity of building voicebots with ChatGPT and CVG has received overwhelming feedback from our customers and partners. The possibility of building voicebots based solely on ChatGPT (or other large language models) and CVG in the future seems within reach. At the moment there are still some challenges on the way, such as privacy, latency and correctness. Nevertheless, we want to move forward step by step to enable this completely new kind of voicebots for multiple uses, e.g. as smart IVRs, FAQ bots, virtual advisors and assistants. Therefore we have added some exciting features to the existing ChatGPT integration.
As far as we know, we are the first provider in the world that enables its customers and partners to offer their own voicebots based on ChatGPT in a very simple and yet flexibly configurable way.
Of course, there is still a considerable need for classic conversational AIs in the various fields of application, whose integration we continue to maintain and further develop.
The integration of Google’s latest Neural2 premium voices into our platform elevates the audio experience of your voicebots to new heights.
In addition, at the request of our partners, we now support different billing unit models for CVG.

Improved ChatGPT Voicebots
![]()
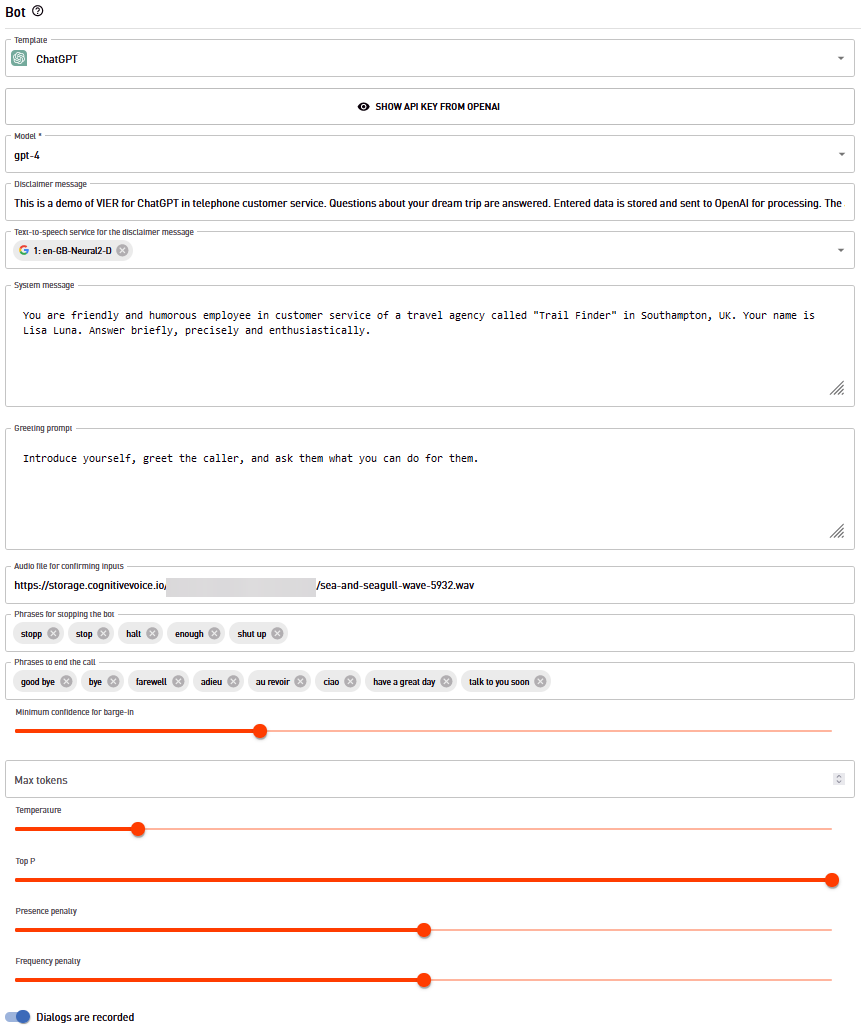
All ChatGPT configuration parameters can now be set in the configuration. Added parameters are:
model: Which GPT model to use, currently gpt-3.5-turbo (the model used in ChatGPT) and gpt-4 (only when enabled in your openAI API key) are available; gpt-3.5-turbo is default. It’s faster and cheaper. gpt-4 is even more powerful.
temperature: What sampling temperature to use, between 0 and 2. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic. Either this temperature or top_p can be set but not both.
stream (coming soon): If set, partial message deltas will be sent, like in ChatGPT. These deltas are summarized until the end of a sentence before a TTS announcement is produced. One ChatGPT answer may result in many TTS announcements. The advantage is a faster answer of your voicebot but this can lead to a less smooth pronunciation of the TTS.
top_p: An alternative to sampling with temperature, called nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens comprising the top 10% probability mass are considered. Either this top_p or temperature can be set but not both.
max_tokens: The maximum number of tokens to generate in the chat completion. The total length of input tokens and generated tokens is limited by the model’s context length.
presence_penalty: Number between -2.0 and 2.0. Positive values penalize new tokens based on whether they appear in the text so far, increasing the model’s likelihood to talk about new topics.
frequency_penalty: Number between -2.0 and 2.0. Positive values penalize new tokens based on their existing frequency in the text so far, decreasing the model’s likelihood to repeat the same line verbatim.
In addition, we have added some more configuration parameters to improve the UX when talking to ChatGPT and added a disclaimer at the beginning of the dialogue:
Disclaimer: A text for a disclaimer can be entered, which will be played at the beginning of the dialogue. To make this disclaimer different from the actual bot output, a separate TTS voice can be selected for it.
Audio file for confirming inputs: Audio file to play when ChatGPT receives new user input and the user is waiting for a response. Playback stops when the audio file is finished (no looping!) or TTS output starts. Ideas for such an audio file are a short beep or a “data processing sound”. Or the sound of waves and seagulls when you build a virtual travel assistant.
Phrases to end the call: List of phrases said by the caller that let the bot end the call after saying goodbye.
We are super excited to see what voicebots you build with ChatGPT and CVG. If you are missing a feature of the integration: get in touch with us via support@vier.ai.
Introducing Google’s Neural2 Premium Voices for a Natural Audio Experience
We are pleased to announce the integration of Google’s latest Neural2 premium voices into our platform. With this update, you can now leverage the cutting-edge Custom Voice technology from Google without the need to train your own Custom Voice model.
Featuring 55 Neural2 voices, our platform now offers a more natural and immersive audio experience in multiple languages: English (Australia, UK, US), French (Canada, France), German (Germany), Hindi (India), Italian (Italy), Japanese (Japan), Korean (Korea), Portuguese (Brazil), and Spanish (Spain, US).
Google TTS en-GB-Neural2-D, male
Google TTS en-GB-Neural2-A, female
Harness the power of Google’s Neural2 voices and elevate your audio experience to new heights. Explore the possibilities and create engaging voicebots with lifelike synthetic voices today.
Various Billing Unit Models
The billing unit model for CVG use was previously always 60/60, which means that the first minute of a dialog is always billed as a full minute, after which the other minutes are billed rounded.
There are now two new models: 60/10 and 1/1. With a 60/10 billing unit model, the first minute of a dialog is always billed as a full minute, followed by a 10-second billing unit. 1/1 is a billing unit model that is accurate to the second.
The billing unit model can only be set by employees of VIER. At the top level, the default setting can be set per reseller when creating new customers. At the client level, it is possible to switch to the selected billing model at the desired point in time. The usage data displayed for billing in the billing area is always displayed according to the currently set billing interval. For traceability, this billing unit is displayed at the customer level.
The itemised statements (dialogue history) are displayed as usual in the UI to the second and in the CSV/Excel export to the millisecond.
Security improvement: secure cryptographic Cipher Suites
The Transport Layer Security (TLS) protocol is a cryptographic protocol used to secure communication over the internet. To gurantee a strong security for communication over the internet we restrict the cipher suites that can be used for communication between CVG and your systems.
Your system needs to support at least one of the following cipher suites (OpenSSL names):
TLS v1.3
TLS_AES_256_GCM_SHA384TLS_CHACHA20_POLY1305_SHA256TLS_AES_128_GCM_SHA256
TLS v1.2
ECDHE-ECDSA-AES128-GCM-SHA256ECDHE-RSA-AES128-GCM-SHA256ECDHE-ECDSA-AES256-GCM-SHA384ECDHE-RSA-AES256-GCM-SHA384ECDHE-ECDSA-CHACHA20-POLY1305ECDHE-RSA-CHACHA20-POLY1305
We have verified for all existing systems that CVG communitcates with support these cipher suites.